Looking Good Info About How To Build A Web Crawler
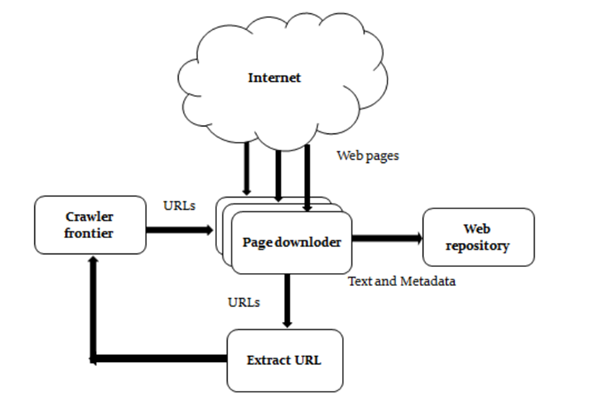
From 0 To 1: How Build A Web Crawler Scratch By Python. Part I. | Lena Li Medium

Build A Crawler To Extract Web Data In 10 Mins | By Octoparse Dataseries Medium

How To Build A Web Crawler? - Scraping-bot.io
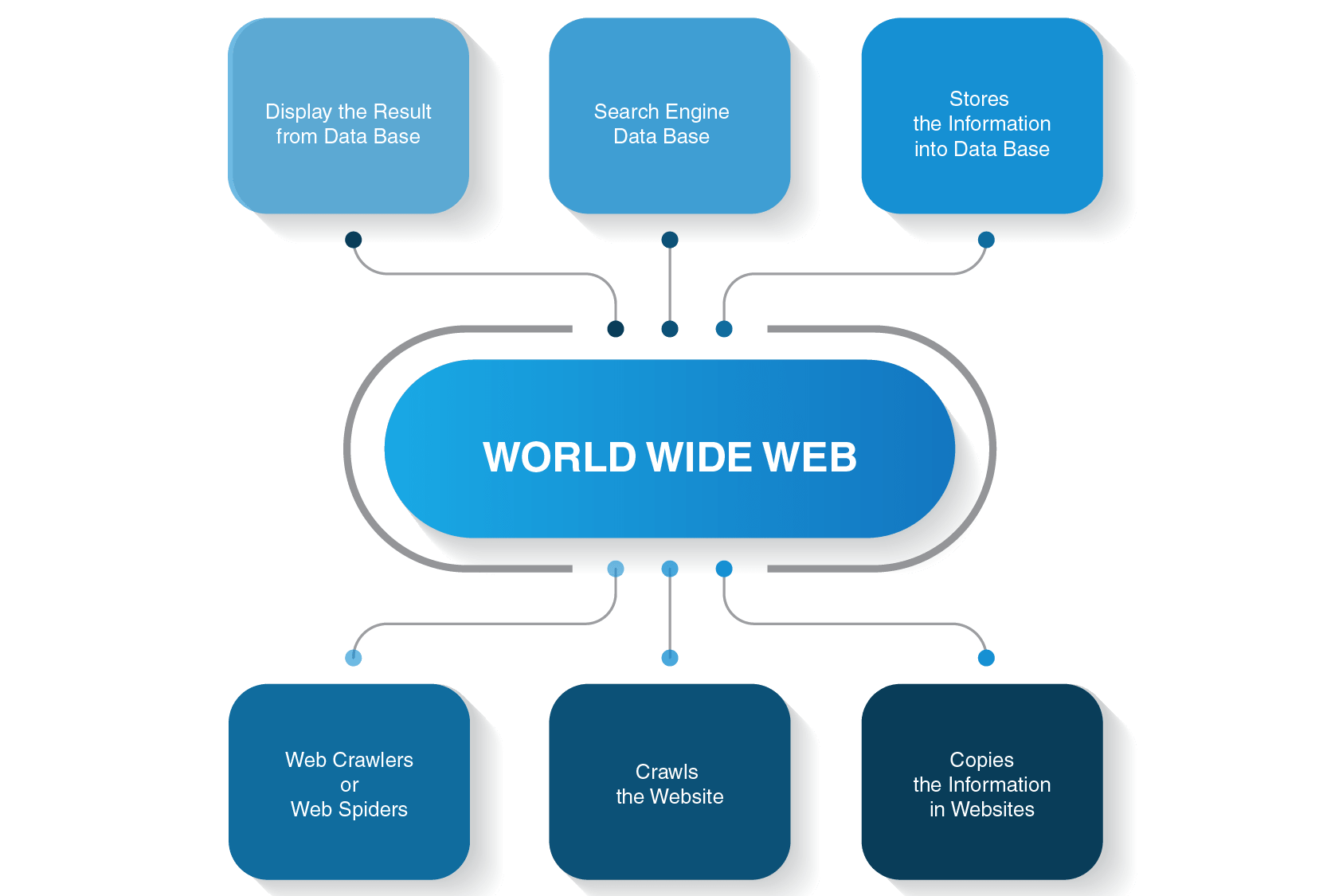
What Is A Web Crawler And How Does It Work | Litslink Blog
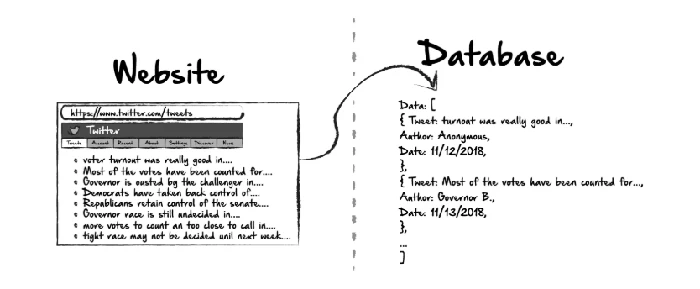
Step-by-step Guide To Build A Web Crawler For Beginners | Octoparse
The first thing to do when configuring the request is to set the url to crawl.
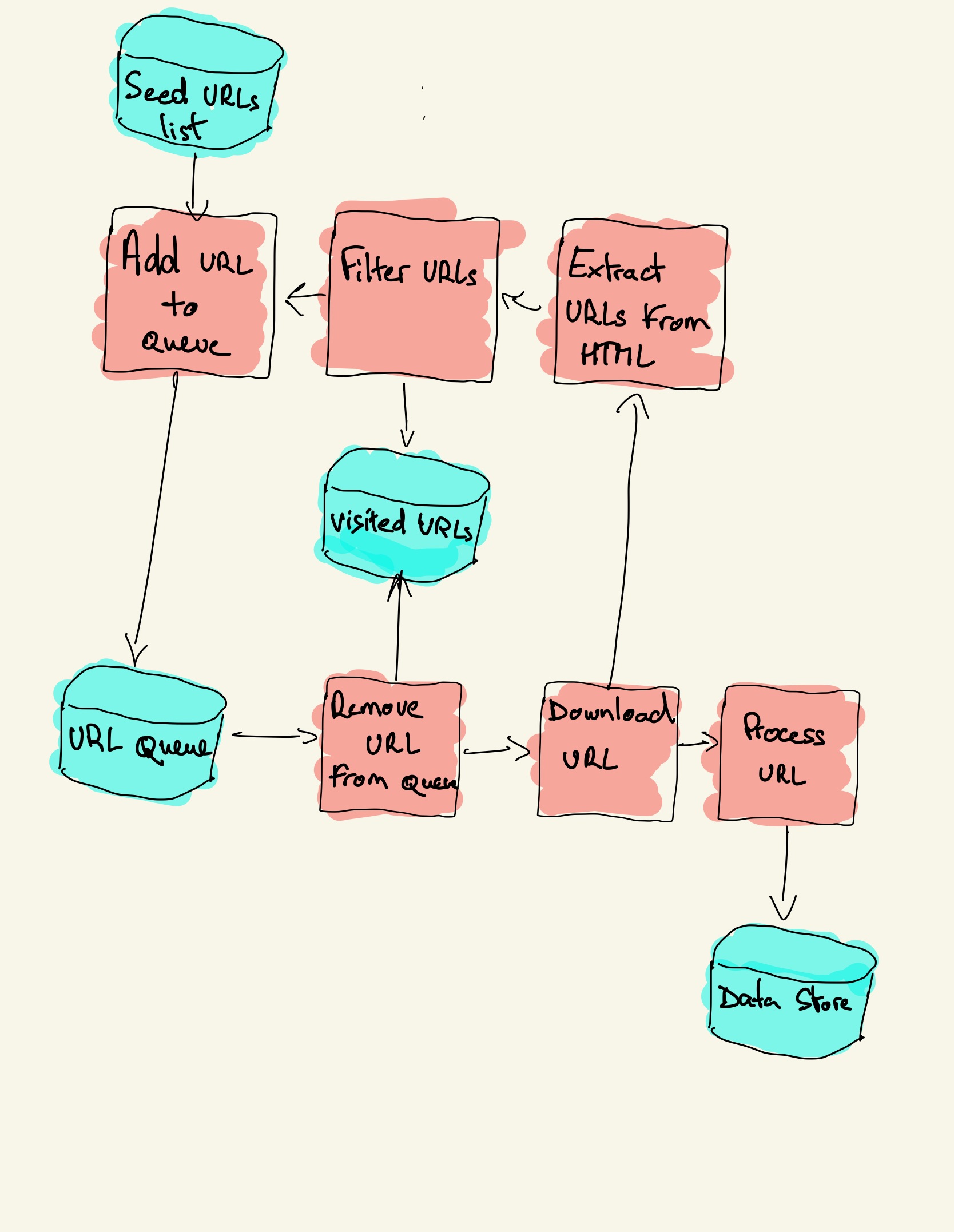
How to build a web crawler. These seed urls are added to. We can do so by calling the uri () method on the builder instance. Pay attention to the purple box, you will notice there is an addition of page=2 in the request url.
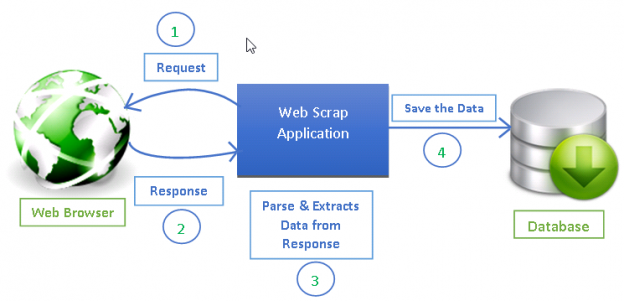
How does a web crawler work? First, click on the page number 2, and then view on the right panel. You might need to build a web crawler in one of these two scenarios:
The crawler will begin from a source url that visits every url. Trandoshan is divided in 4 principal processes: Here, kindness means that it respects the rules set by robots.txt and avoids frequent website visits.
We’ll also use the uri.create () method to. We can do so by calling the uri () method on the builder instance. Here are tools which you can use to build your own web crawler:
Custom script to store results, monitor pages and send rss n email if. All you have to do is provide the url of the site you. This is provided by a seed.
The working mechanism for web crawlers is simple. Now, to the tutorial’s core, we will build a web crawler that uses the bfs algorithm to traverse web pages. The web crawler should be kind and robust.

Make Your Own Web Crawler - Part 1 The Basics Youtube

How To Build A Web Crawler In Python From Scratch - Datahut

Web Crawler - Wikipedia

Scaling Up A Serverless Web Crawler And Search Engine | Aws Architecture Blog
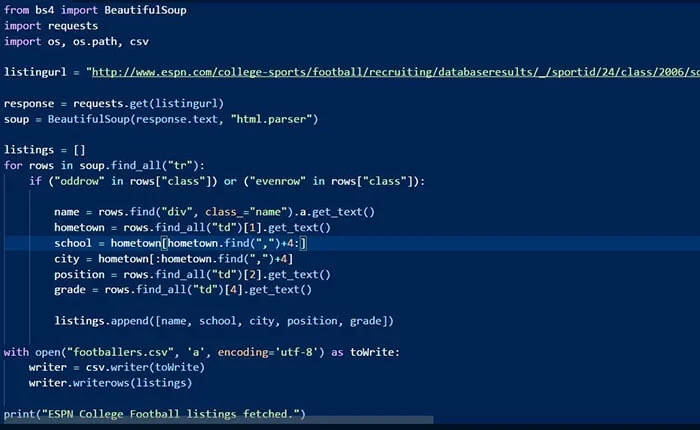
Step-by-step Guide To Build A Web Crawler For Beginners | Octoparse
Scrapy Python: How To Make Web Crawler In Python | Datacamp

How To Build A Serverless Web Crawler | Cloud Guru

Step-by-step Guide To Build A Web Crawler For Beginners | Octoparse

How To Build A Simple Web Crawler | By Low Wei Hong Towards Data Science
Web Crawling With Python | Scrapingbee

Python Programming Tutorial - 25 How To Build A Web Crawler (1/3) Youtube

How To Build A Web Crawler In Python From Scratch - Datahut
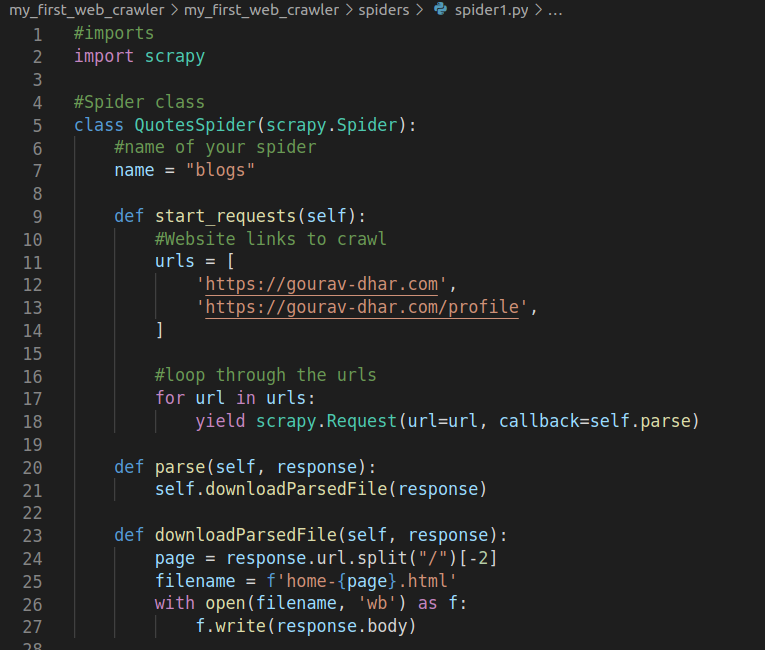
How I Created My First Web Crawler! | By Gourav Dhar Level Up Coding
